
-
3D는 로봇, 컴퓨터비전, AI모든 분야에서 중요하게 여겨짐반응형
Why?
우리가 바로 3D 세상에서 살고있기 때문!
- 따라서 3D 공간에 대한 이해가 있어야 우리에게 실질적으로 도움이 될 수 있음
3D applications
- AR/VR
- 3D printing
- Medical applications
3D를 관찰하는 방법
이미지는 3D세상을 2D공간에 projection 한 것 이다, 즉 3D와 2D는 프로젝션 관계
이를 가능하게 해주는 장치 중 하나가 카메라인데 재밌는 것은 아래와 같이 서로 다른 각도에서 찍은 2D이미지를 통해 3D로의 복원이 가능하다는 것이다.

- 각 사진에서 3D로 복원할 부분을 일직선으로 쭉 그은뒤 교차하는 부분을 3D포인트라고 하고 이를 Triangulation이라고 한다. (이를 위해서는 단순 사진 2장이 필요한게 아니라 카메라의 위치 정보도 가지고 있어야한다)
3D 데이터의 표현법
- 2D 이미지는 2D 어레이구조의 각 필셀의 RBG값으로 표현된다
그렇다면 3D의 표현은 어떻게 될까?
- 2D의 표현과 달리 3D의 표현은 유니크하지 않고 아래와 같이 여러방법이 있다

- Multi-view images : 다양한 각도에서 사진을 찍은 뒤 보관
- Volumetric : 2D이미지와 가장 비슷한 표현 방법, 3D space를 격자로 나눠 해당 object가 그 공간을 차지하고 있는지 없는지로 표현
- Part assembly : 기본적 도형들을 합쳐 표현
- Point cloud : (x,y,z)점들을 모아 표현
- Mesh(Graph CNN) : triangle mesh가 주로 사용된다. (x,y,z)같은 포인트들이 삼각형 형태 계속 이어져서 표현
- Implicit shape : 최근에 각광받는 방법, 함수와 교차하는 해들을 모아 형상을 구성
3D datasets
- ShapeNet

55개의 카테고리에 대해서 51,300개수의 가상으로 만들어진 오브젝트로 구성된 데이터셋
- PartNet(ShapeNetPart2019)

ShapeNet의 개선버전, 하나의 물체마다 annotation되어있다. 26,671개의 3D 모델에 대해서 573,585개의 파트를 구별해놓은 데이터셋.
예를 들어 캐리어의 경우 바퀴까지 구분이 될 정도로 디테일해서 segmentation에 대해 유용하게 사용될 수 있다.
- SceneNet

500개의 RGB-Depth pair의 인위적으로 만든 실내 영상 데이터셋
- ScanNet

RGB-Depth pair가 되어있고 250만개의 view로 구성되어 있는 실제데이터
- Outdoor 3D scene datasets

3D tasks
- 뉴럴네트워크 같은 다양한 3D모델을 사용해 Recognition, Detection 다양한 task에 사용
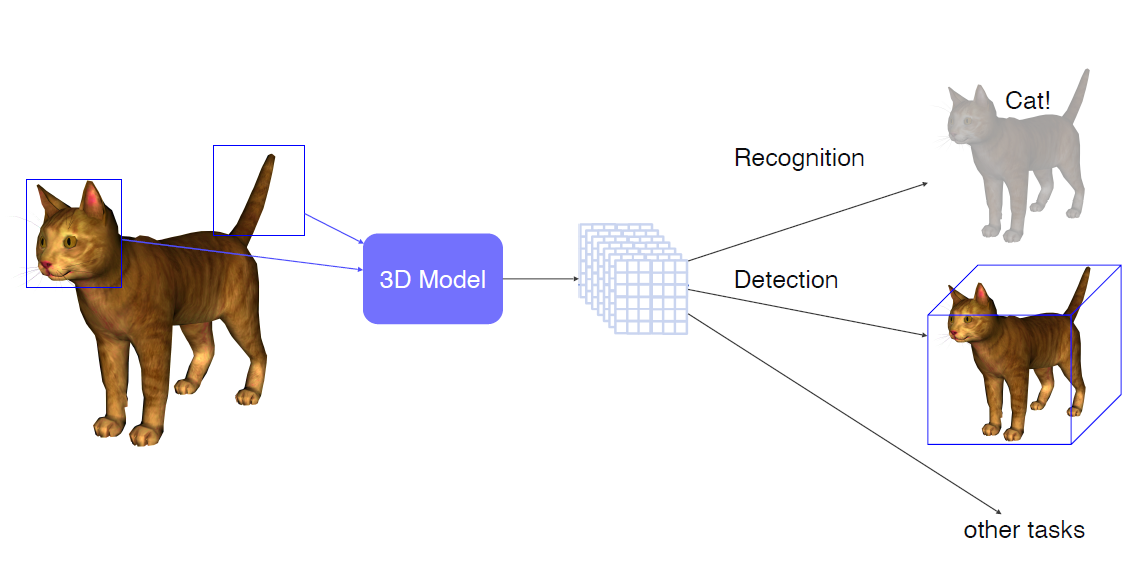
3D object recognition

- 2D의 경우 이미지가 들어갔을 때 label을 배출
- 3D의 경우도 비슷하게 Volumetric CNN같은 걸 사용해서 물체를 분류
3D object detection
- 3D object detection은 이미지나 3D space 둘 다 가능
- 이는 자율주행에서 유용하게 사용된다.

3D semantic segmentation
- 각 물체에 대해서 Semantic segmentation

Conditional 3D generation
Mesh R-CNN
- 2D이미지를 넣으면 3D mesh를 출력값으로 반환

Mesh R-CNN
- Mask R-CNN에 3D branch가 추가 됨

반응형
'⚡AI > AI' 카테고리의 다른 글
| Cost Function & Activation Function (0) | 2022.03.24 |
|---|---|
| Local Minima 문제에도 불구하고 딥러닝이 잘 되는 이유는? (1) | 2022.03.23 |
| [DL]Optimizer (0) | 2022.02.10 |
| [DL]딥러닝 개요 (0) | 2022.02.09 |