비선형모델의 학습방법을 AraBoza
아래와 같이 데이터 X와 가중치 W사이의 행렬곱과 bias b벡터로 구성된 식이 있다고 가정해보자
이 때 우리는 W와 b를 수정해나가면서 정답과 가까운 O를 예측하는 것이 목표이다!
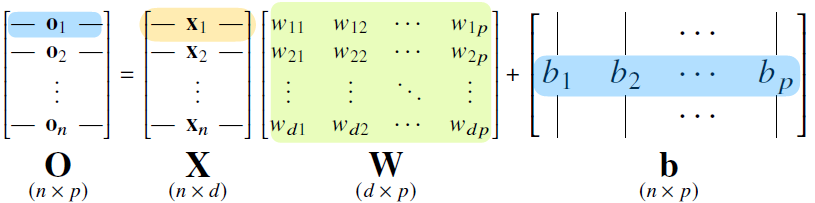
- 계산 결과를 살펴보면 n차원이던 X벡터가 p차원으로 변환되는 것을 살펴볼 수 있다.

- 다중분류 문제를 풀기위해서 출력벡터 O에 소프트맥스(softmax)라는 함수를 합성하면 특정 클래스에 속할 확률로 해석할 수 있는 확률벡터로 변환해준다
- 아래는 소프트맥스를 합성한 식이다.

- 추론을 할 때는 원-핫(one-hot)벡터를 사용해 sofrtmax를 사용하지는 않는다
- one-hot벡터 : 최대값을 가진 주소를 1로 나머지를 0으로 표현
- 여기까지만 본다면 우리는 단순히 선형모델을 푸는 것밖에 되지 않는다, 비선형모델을 풀기 위해서는 무엇인가가 추가로 필요하다
- 이를 위해 활성함수(activation function)이 추가된 신경망이라는 개념이 도입된다
- 신경망 = 선형모델 + 활성함수
- 아래와 같이 활성함수를 거쳐 새로운 잠재벡터를 나타낸다

- 아래는 여러가지 활성함수이다
- 예전엔 sigmoid, tanh가 많이쓰였지만 기울기소실문제로 최근 딥러닝에서는 ReLU가 주로 쓰인다.

- 여기서 아래와 같이 신경망이 여러층 합성된다면 이것을 다층(mulit-layer) 퍼셉트론(MLP)라고 부른다
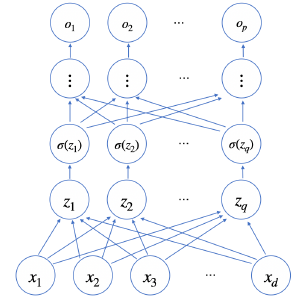
- 또한 순차적인 신경망 계산은 순전파(foreward propagation)이라 부른다, 이는 학습이 아닌 연산만 하는 과정이다
Q) 왜 층을 여러개를 쌓을까?
- "이론"적으로는 2층 신경망으로도 임의의 연속함수를 근사할 수 있다
- 그러나 층이 깊어질수록 목적함수를 근사하는데 필요한 뉴런의 숫자가 훨씬 빨리 줄어 들어 효율적인 학습이 가능하다(층이 얕게되면 필요한 뉴런의 숫자가 늘어나서 넓은 신경망이 되어야한다)
- (But, 최적화를 시키기 위한 노력은 더 많이 들게 된다... )
- 이제 목적함수를 근사하기 위해 W를 계속 수정해나가야하는데 이를 위해 딥러닝에서는 역전파(Backpropagation)알고리즘을 사용한다.
- 이는 미분값을 저장하기 때문에 foreward propagation과 달리 메모리를 사용하게 된다.

반응형
'⚡AI > ∃Mathematics' 카테고리의 다른 글
| 공분산과 상관계수 (0) | 2022.02.03 |
|---|---|
| 딥러닝을 위한 통계학 맛보기 (0) | 2022.01.21 |
| 딥러닝을 위한 확률론 맛보기 (0) | 2022.01.21 |
| 경사하강법(Gradient Decent) (0) | 2022.01.19 |
| 벡터&행렬이란 무엇인가? (0) | 2022.01.17 |